Reactive Programming is really great to write event driven applications, data driven applications, and asynchronous applications. However it can be difficult to find a good way to structure the code. Fortunately for Javascript developers, there is cyclejs. So I developed a similar framework for Python and RxPY:: Cyclotron.
edit: Updated examples to RxPY v3, and cyclotron drivers list.
Cyclotron is a functional and reactive framework. It allows to structure a reactive code in a functional way. More specifically, functional means the following:
- Pure code and side effects are clearly separated
- All the code is implemented via functions (no class)
Moreover it is specifically design to write reactive code:
- All components communicate via Observables
- Observables cycles are naturally handled
The following pictures shows how a Cyclotron application is structured:
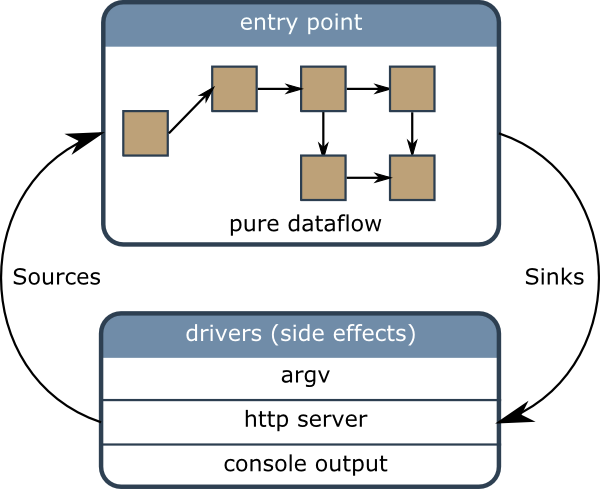
There are two parts in a cyclotron application: A pure data-flow, and side effects. The pure data-flow is composed of pure functions. Pure functions are functions whose behavior is deterministic. This means that their output depends only on their input parameters. The pure data-flow part is where the application logic is implemented.
A side effect is any function that is not a pure function. For example a function that take no parameter as input and returns the current date is a side effect. Also any function that work on IO is a side effect because its result depends the underlying IO.
The pure data flow and the side effects communicate together via Observables. By convention, the output Observables of the pure data flow (that is also the input of side effects) are called sinks. The input Observables subscribed by the pure data-flow (being also the output of the side effects) are called sources.
Note how the pure data-flow and the side effects form a directed cyclic graph: They depend on each other. Managing such Observable cycles is not always easy. Cyclotron handles naturally such cycles between the pure data-flow and the side effects: A bootstrap function connects circularly the pure entry point with the side effects.
Let's see an example application. A hello world consisting in an asynchronous http server that sends back the content received on the "/echo" url. This echo server uses AsyncIO for the asynchronous management of the IO operations. The design of this application is shown on the following reactivity diagram:

A reactivity diagram uses the representation of UML activity diagrams, but with a different meaning. An activity diagram represents a code flow, and each link represents a call to a function or a method. A reactivity diagram represents a data-flow, and each link represents an Observable. So each action being described is called for each items emitted by the Observable.
On this example, the http server is a side effect, represented with a rectangle with the upper-right corner bent. Operators or actions are represented as rounded rectangles. In this example each request received from the http server is mapped to a response. The thick horizontal line represents a merge operator. Note that this very simple example already contains an Observable cycle. No let's see the implementation.
We first need some imports:
from collections import namedtuple from cyclotron import Component from cyclotron.asyncio.runner import run import cyclotron_aiohttp.httpd as httpd import rx import rx.operators as ops
Namedtuples are heavily used in Cyclotron. Using named tuples has several benefits:
- Their fields can be accessed directly from their names. So this syntax is less verbose than using Dicts: A foo field is accessed as a.foo instead of a['foo'].
- Namedtuples - like tuples - are immutable. Immutability is one foundation of functional programming. The idea here is to embrace immutability via namedtuple as much as possible.
Then several Cyclotron imports are used, as well as the Observable definition from RxPY.
The next step is then defining the Source, Sink, and drivers used by the application:
EchoSource = namedtuple('EchoSource', ['httpd']) EchoSink = namedtuple('EchoSink', ['httpd']) EchoDrivers = namedtuple('EchoDrivers', ['httpd'])
Since this application is very simple, there is a single source, a single sink, and a single driver being used. The http driver needs both a source and a sink. Some drivers may be source only (they only emit items), and some drivers may be sink only (they only consume items).
Then are the main function and the bootstrapping of the entry point and the drivers:
def main(): run(Component(call=echo_server, input=EchoSource), EchoDrivers(httpd=httpd.make_driver())) if __name__ == '__main__': main()
The run function connects the entry point of the application (the echo_server function) with the httpd driver. Finally, here is the pure data-flow of the application:
def echo_server(source): init = rx.from_([ httpd.Initialize(), httpd.AddRoute(methods=['GET'], path='/echo/{what}', id='echo'), httpd.StartServer(host='localhost', port=8080), ]) echo = source.httpd.route.pipe( ops.flat_map(lambda i: i.request) ops.map(lambda i: httpd.Response( context=i.context, data=i.match_info['what'].encode('utf-8')))) ) control = rx.merge(init, echo) return EchoSink(httpd=httpd.Sink(control=control))
The echo_server function takes sources as input and returns sinks. These are objects of Observables. The init Observable contains three items, used to initialize the http server. Here a /echo route is defined, and the server listens on localhost, port 8080
The echo Observable is the handler of the echo route. It listens to the source of the http server and subscribes to the Observable of the echo route. Then, for each item received on this Observable, a response is created, based on the request's path.
After that the init and echo Observables are merged so that they can be provided as a sink to the http driver. The whole code is available on the GitHub repository of cyclotron-aiohttp.
You can start the server in a console:
python3 http_echo_server.py
And then test it from another console:
$ curl http://localhost:8080/echo/hello hello $ curl http://localhost:8080/echo/foo foo
Cyclotron is a small project, already stable and used in production, so feel free to try it in your own projects. Currently, cyclotron is composed of several packages:
- cyclotron, the core part of the project
- cyclotron-std, contains drivers and adapters for the python standard library
- cyclotron-aiohttp, cyclotron-aiokafka, and cyclotron-consul contain drivers for different protocols and technologies.
They are available from pypi. The sources and links to documentation is available on GitHub.
Romain.
 Interested in reactive programming ? Here is my book on
Reactive Programming with Python. I wrote this book to explain how to develop RxPY applications step by step.
Interested in reactive programming ? Here is my book on
Reactive Programming with Python. I wrote this book to explain how to develop RxPY applications step by step.