ReactiveX is a wonderful framework that allows to write event based code in a very elegant and readable way. Still, getting started in it can be challenging, and intimidating. In practice once you understand few key principles of ReactiveX, you can start writing reactive code easily.
The aim of this article is to explain these keys principles, and show how they apply though a simple example. By the way, the first half of this article is language agnostic. So feel free to read it even if you use another programming languages than Python.
Before reading on, be aware of one important thing: Reactive Programming is addictive ! Once you start thinking as a data flows instead of control flows, you trend to consider that it solves problems better than other programming approaches, and you use reactive programming more and more.
Reactive Programming and ReactiveX
So what is reactive programming ? It is a way to write event driven code. The name comes from the fact that a reactive code is composed of entities that react to events being emitted by sources. These entities apply transformations on these events, and return other events as a result. So these entities - named operators - can be chained together, to create computation graphs.
Reactive computation graphs are always directed. They flow in only one way. Some graphs are Directed Acyclic Graphs - DAG - like this one:
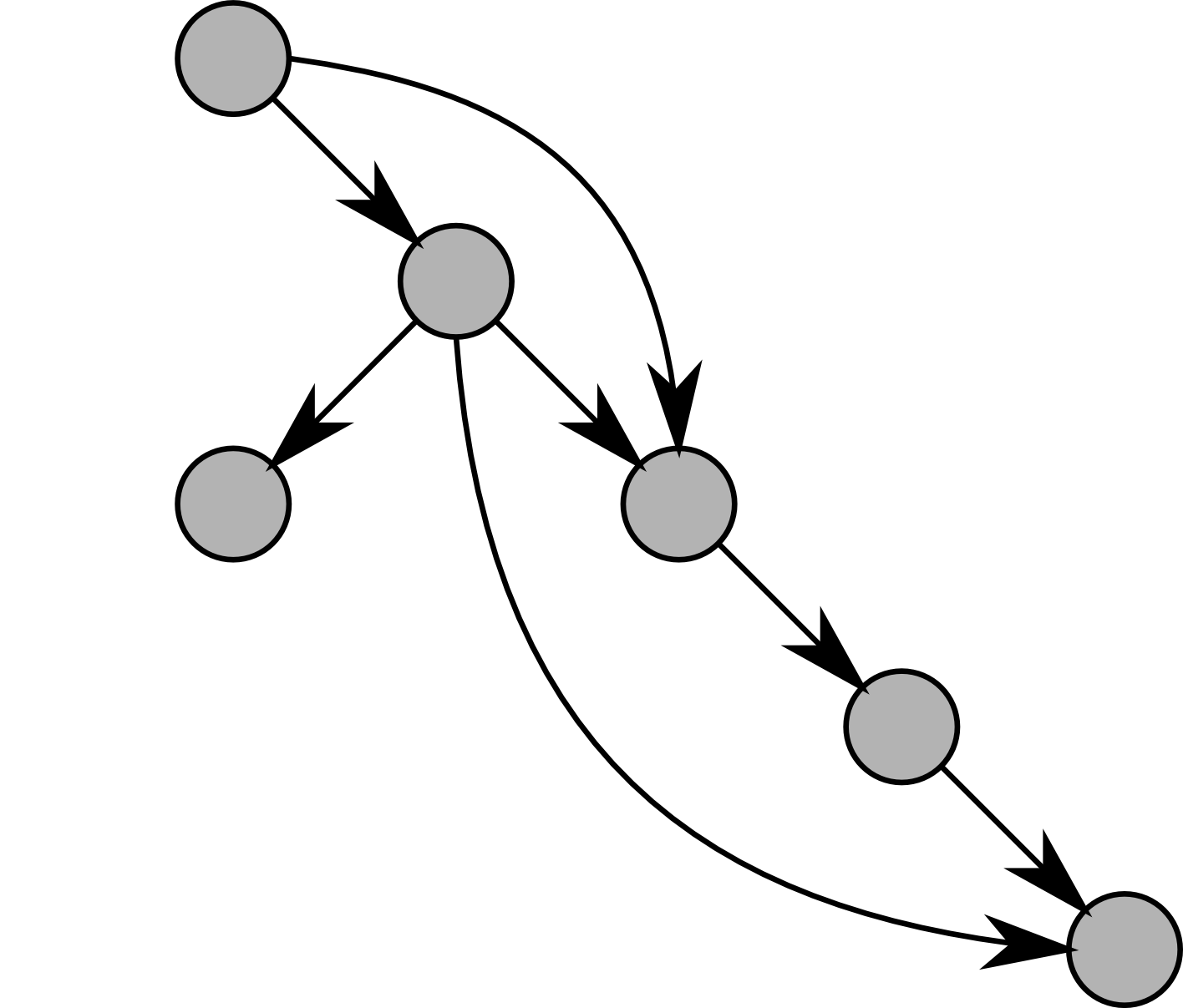
On this diagram the nodes represent computations, and the edge the link between computations.
Some graphs may also be Cycle Graphs like this one:
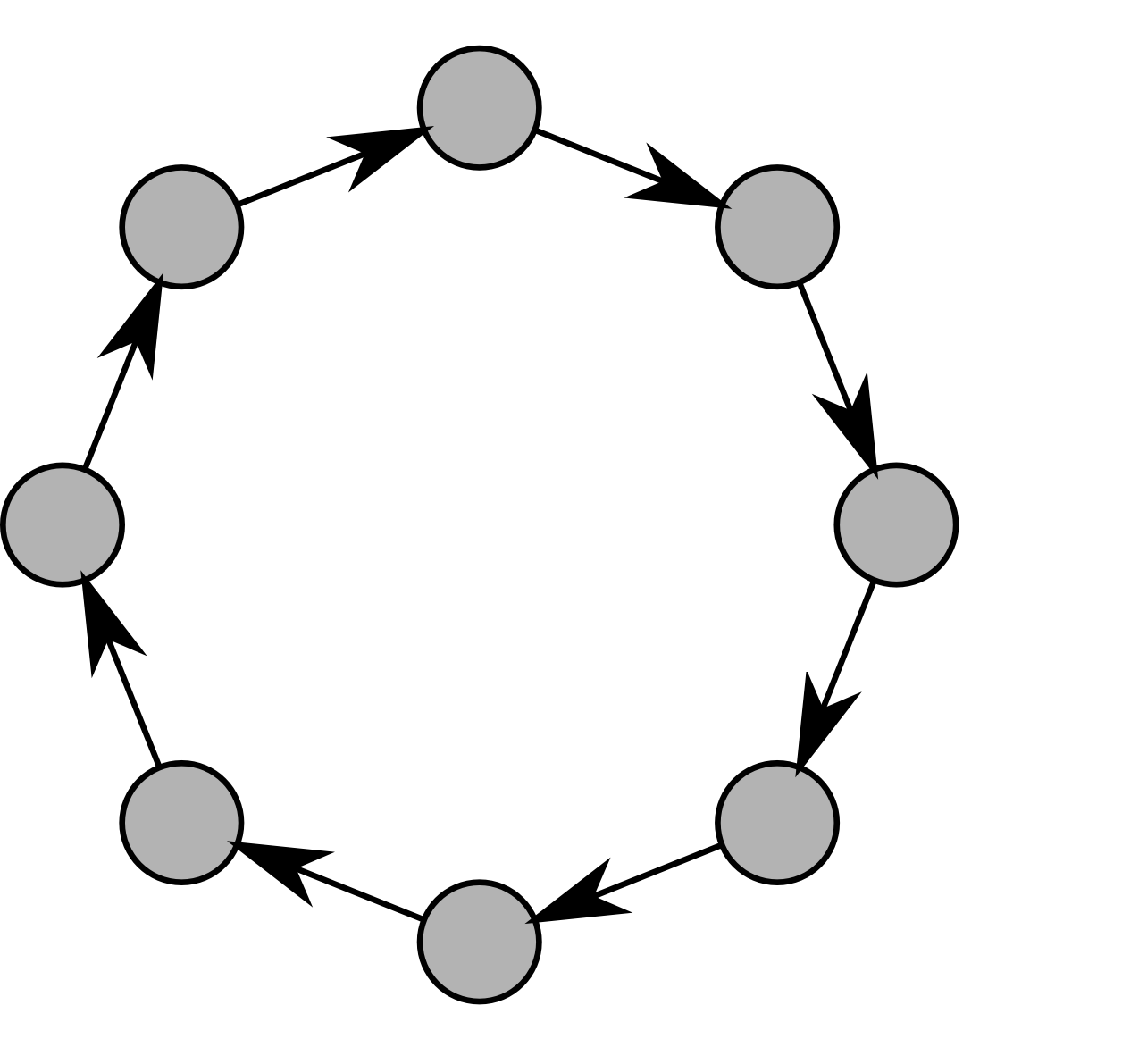
Cycle graphs are very common when writing a fully reactive application. Most of the time the major part of an application graph is acyclic, and a sub-part may have cycles.
ReactiveX is the most popular implementation of Reactive Programming libraries. One reason is that it was one of the firsts reactive libraries. It was initially developed by Microsoft for the .net platform. Since 2012 the code is open source, and has been ported to more than 20 programming languages.
The python implementation of ReactiveX is RxPY. The library is available on pypi and can be installed with pip:
pip3 install rx
Observable, Observer, Operator
The foundation of ReactiveX is based on only few key principles described in the Observable Contract. Once you understand these principles, you will clearly understand the behavior of any ReactiveX code.
The base entity in ReactiveX is the Observable. An Observable is an entity that is a source of items. Item is the ReactiveX term for an event. You can consider that an Observable is a stream of event.
The second entity is the Observer. An Observer is the entity that subscribes to Observers, so that it can process items as they are emitted. The subscription to an Observable is explicit. This means that an Observable does not emit items until an Observer subscribes to it. When an Observable is created, no data flow occurs. The data flow starts at subscription time, not at creation time.
We can then combine an Observer and an Observable to create an Operator. An operator subscribes to a source Observable, applies some transformations to the incoming items, and emits new items on another Observable.
This is all you need to understand how ReactiveX works ! We will go in more details in the following paragraphs, but it all ends up to understanding these four notions: Observable, Observer, Subscription, Operator.
Marble Diagrams
A picture is worth a thousand words.
This is the motto of marble diagrams: A by example way to represent the behavior of an operator. You will find such diagrams almost everywhere in documentations. Consider the map operator. This operator takes items from a source Observable, applies a transformation function, and returns a sink observable with the transformation function applied on source items. This is a very simple behavior, but rather verbose to explain in plain English. The marble diagram of the map operator is an easier way to explain this, and also an intuitive way to understand how ReactiveX works:
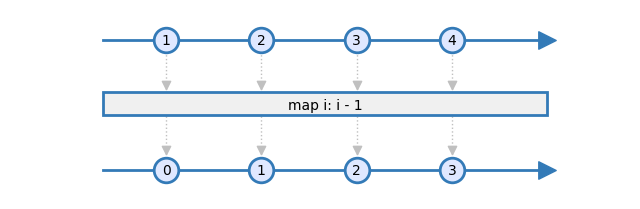
There are three parts in this diagram:
- The top arrow represents the source observable: When being subscribed, this source Observable emits the numbers 1 to 4.
- The rectangle represents the computation done by the operator. In this example, one is subtracted to each received item.
- The bottom arrow represents the sink Observable. As a result of subtracting 1 to each item, it emits items 0 to 3.
On marble diagrams, time increases from left to right. So the leftmost item is emitted before the rightmost. The end of the arrows can have different shapes, each indicating different ways that the Observable completes:
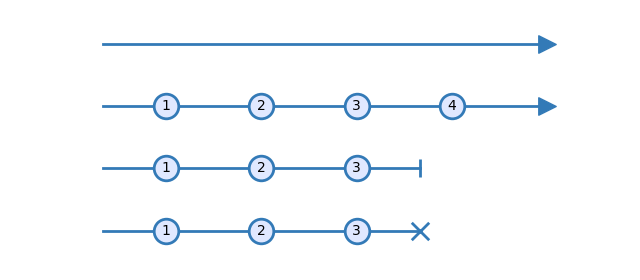
A Line ending with an arrow means that the Observable will continue to emit items in the future. Circles on the line are time positions when items are emitted.
A line ending with a pipe - | - indicates that the Observable completes on success. No more items can be emitted after.
A line ending with a cross - X - indicates that the Observable completes on error. No more items can be emitted after.
Reactivity Diagrams
Reactivity diagrams are another kind of visualization. They are used to describe the behavior of an application or a component. They are similar to UML Activity Diagrams, but they describe a data flow instead of a control flow. Let's consider a simple application that takes a source observable as input, decrease the value, and keep only even values. Here is the reactivity diagram of this application:

The black circle indicates a source Observable. The rounded rectangles are operators. Here we chain two operators: map and filter. The encircled black circle is a sink of the data flow.
More complex graphs can be described in a similar way. Reactivity diagrams are a good way to work on architecture before coding. See here another simple example with a cycle graph:

Show Me some code !
You are now ready to read and write ReactiveX code ! Let's implement the code corresponding to the first reactivity diagram of the previous section. We need two imports to use the ReactiveX operators:
import rx import rx.operators as ops
The first import is to use utility functions and factory operators. Factory operators are operators that create Observable from an external source of data instead of an Observable. The second import is a shortcut for using all other operators.
The first step is to create a source Observable. We do not use real data here, but instead we create an Observable from a list. This is done with the from_iterable factory operator:
import rx import rx.operators as ops source = rx.from_iterable([1, 2, 3, 4])
Then we build the computation graph. This one is composed of two operators: map and filter.
import rx import rx.operators as ops source = rx.from_iterable([1, 2, 3, 4]) source.pipe( ops.map(lambda i: i - 1), ops.filter(lambda i: i % 2 == 0), )
The pipe operator allows to chain other operators. It is an easy and readable way to create graphs. The map and filter operators take functions as parameters. We use lambdas here for these simple computations.
You can execute this code already. However, remember that nothing will happen yet: The graph is created but nobody subscribed to it, so no data flows yet. Let's do that to consume the source observable:
import rx import rx.operators as ops source = rx.from_iterable([1, 2, 3, 4]) source.pipe( ops.map(lambda i: i - 1), ops.filter(lambda i: i % 2 == 0), ).subscribe( on_next=lambda i: print("on_next: {}".format(i)), on_completed=lambda: print("on_completed"), on_error=lambda e: print("on_error: {}".format(e)) )
The subscribe method... subscribes to an observable. It takes three callbacks as arguments. These callbacks will be called at different times:
- on_next is called each time an item is received.
- on_completed is called when the observable completes on success.
- on_error is called when the Observable completes on error.
Note that according to the Observable Contract, the on_next callback will never be called after the on_completed and the on_error callbacks.
There is a final step needed to clean up the resources on completion. The subscription creates some resources. These resources have to be cleaned up when they are not needed anymore. For this, the subscribe method returns a Disposable object. The dispose method of this Disposable object can be called to clean up these resources:
import rx import rx.operators as ops source = rx.from_iterable([1, 2, 3, 4]) disposable = source.pipe( ops.map(lambda i: i - 1), ops.filter(lambda i: i % 2 == 0), ).subscribe( on_next=lambda i: print("on_next: {}".format(i)), on_completed=lambda: print("on_completed"), on_error=lambda e: print("on_error: {}".format(e)), ) disposable.dispose() print("Done!")
Error Management
Ok, our code is fine, but what happens if the source observable contains strings instead of integers ? For sure the map operator will raise an exception because subtracting 1 to a string is not allowed in python. Ideally, this should be handled explicitly, so that we can deal with this error. The good news is that this is already the case.
Replacing the source observable with this:
source = rx.from iterable([1, ”foo” , 3, 4])
gives the following result:
$ python demo1_error.py on_next: 0 on_error: unsupported operand type(s) for -: ’str’ and ’int’ Done!
The on_error callback has been called with the exception raised by the map operator as an argument. So what happened here ? What is the consequence on the filter operator that is executed after the map operator ?
The full explanation - sometimes called Railway Oriented Programming - is in this figure:
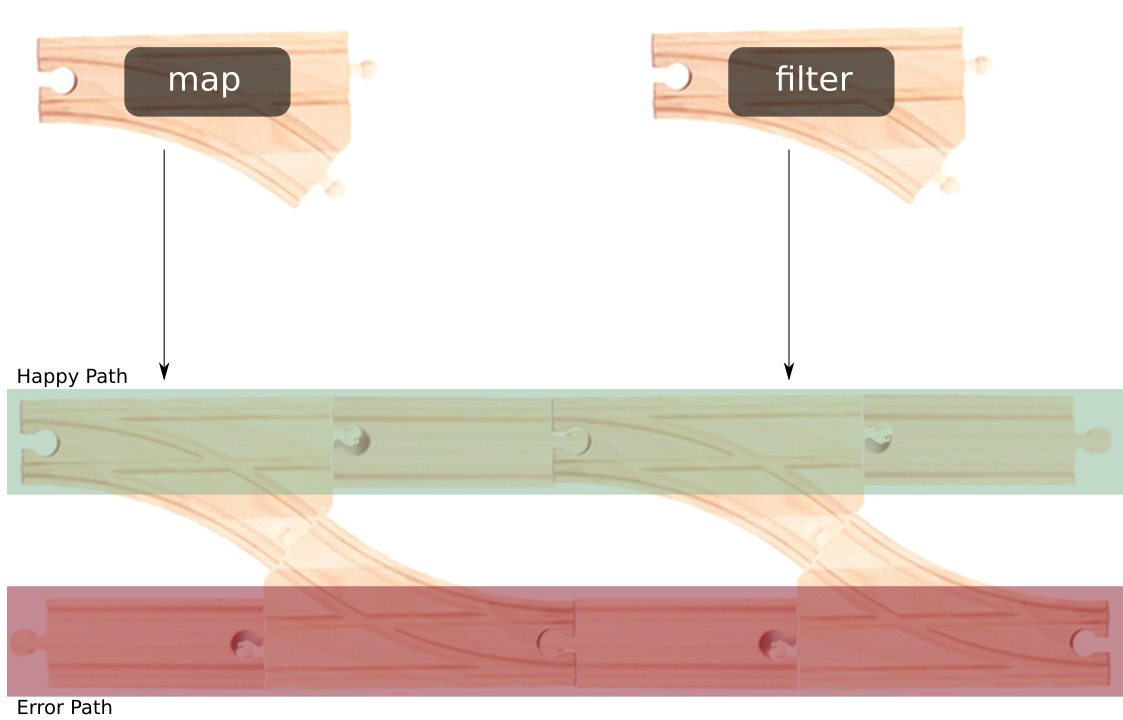
One can see an operator as working on two data flows in parallel:
- The happy path processes all incoming items.
- The error path processes the errors.
As a consequence, here is the behavior of our application: Each time an item is emitted, it goes through the happy path of the map operator (i.e. its value is decreased). If all goes well, the resulting item continues on the happy path of the filter operator. On success, the on_next callback is called.
In case of error in the map function, the map operator catches the exception, and emits it on the error path. The exception is forwarded to the error path of the filter operator. The filter operator just forwards it downstream, and the on_error callback is called.
So operators deal explicitly with errors. There are also some operators dedicated to error management, such as retrying subscriptions, or generating errors on timeout.
The great thing with this structure is that in many cases, you have error management for free. For people using functional programming, this is an implementation of the Try monad.
Concurrency
The example that we implemented is blocking: All the computation is done in the call to the subscribe method. This is the default behavior of ReactiveX, but it is not always desirable. Sometimes there is a need for concurrency management, either IO or CPU. ReactiveX deals with concurrency via dedicated operators and schedulers.
Schedulers are objects that manage threads and event loops. RxPY implements schedulers to deal with CPU concurrency via threads and thread pools. It also provides schedulers for IO concurrency with AsyncIO, Twisted, GEvent and Eventlet.
For more details and examples on concurrency, see the RxPY documentation.
Conclusion
You now have all the keys to start using Reactive Programming. Understanding these concepts is all you need to understand existing code and write your own one. Start playing with the library, get familiar with the existing operators. The real hard part of ReactiveX is to know the existing operators to avoid re-writing them in you code !
The RxPY documentation contains examples on all key features, and - hopefully - detailed information on each operator.
Once you are familiar with this, the other concepts like multicasting, hot/cold Observables, and higher order Observables will be easy to grasp.
 Interested in reactive programming ? Here is my book on
Reactive Programming with Python. I wrote this book to explain how to develop RxPY applications step by step.
Interested in reactive programming ? Here is my book on
Reactive Programming with Python. I wrote this book to explain how to develop RxPY applications step by step.