Every technology, paradigm, or framework relies on some foundations. ReactiveX is no exception. Whether you are a beginner or fluent in it, you will rely on three base operators: Map, Filter, and Scan. These are the three Musketeers of ReactiveX. Independently, they are the basic blocs to create full applications. Combined together, they let you implement almost any transformation you may need.
If you are new to ReactiveX, I suggest that you first read my introduction article before continuing.
Map
Let's start with the most basic operation and the one that is probably the most used: map. The map operator applies a transformation function on each source item and emits the result of this transformation. Here is the marble diagram of the map operator:
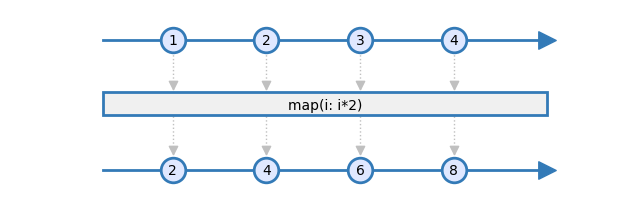
In this example, the source observable emits four items: 1, 2, 3, and 4. The transformation consists of multiplying each item by two. As a result, the operator also emits four items: 2, 4, 6, and 8.
Let's consider a case where input items are strings, and we want to capitalize them. The implementation in RxPy is the following:
import rx import rx.operators as ops source = [ "each night", "the seed grows up", "in the store galaxy", ] rx.from_(source).pipe( ops.map(lambda i: i.capitalize()) ).subscribe( on_next=print, on_error=print, on_completed=lambda: print("Done!") )
By running this example, we have the following result:
Each night
The seed grows up
In the store galaxy
Done!
The three strings have their first word being capitalized. We can also chain several map operations. This is often better than using a single map that does many things: This can improve the readability of the program. For example, we can replace spaces with a minus as another step:
rx.from_(source).pipe( ops.map(lambda i: i.capitalize()), ops.map(lambda i: i.replace(" ", "-")), )
Filter
The second base operator is filter. This operator allows to remove items from an observable:
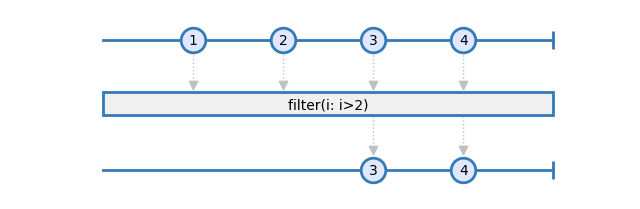
In this marble diagram, only items with a value bigger than two are forwarded. The others are dropped.
Let's apply this operator to our string dataset. We can drop lines containing the word "galaxy" this way:
import rx import rx.operators as ops source = [ "each night", "the seed grows up", "in the store galaxy", ] rx.from_(source).pipe( ops.filter(lambda i: "galaxy" not in i.lower()) ).subscribe( on_next=print, on_error=print, on_completed=lambda: print("Done!") )
This gives the following result:
each night
the seed grows up
Done!
Scan
The first two operators that we used were stateless. This means that their output only depends on their input. In functional programming, they are named pure functions. But sometimes we need operations that also depend on the previous values that have been received. This is typically the case of the computation of a sum or a mean. These are stateful operations. The scan operator can be used to implement such transforms:
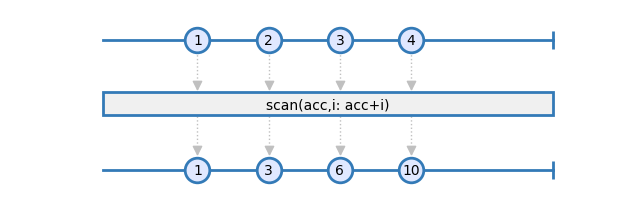
This marble diagram represents the implementation of a sum.
- The scan operator takes a function as an argument.
- This function has two input arguments: An accumulator and the item to process.
- The result of this function is an updated accumulator.
- When several items are processed, the accumulator provided as an input argument is its value as returned in the previous call.
So in this example, considering than the accumulator is initialized with 0, the following steps happen:
- 1 is emitted: acc=0, i=1, returned acc is 0+1=1
- 2 is emitted: acc=1, i=2, returned acc is 1+2=3
- 3 is emitted: acc=3, i=3, returned acc is 3+3=6
- 4 is emitted: acc=6, i=4, returned acc is 6+4=10
Now let's consider that our source data is received in pieces, delimited with newlines:
source = [ "each ni", "ght\n", "the seed grow", "s up\n", "in the store galaxy\n", ]
We want to reconstruct each string and remove the newline. This can be implemented with the scan operator. Consider the following function:
def unframe(acc, i): lines = i.split('\n') lines[0] = acc[1] + lines[0] return ( lines[0:-1], lines[-1] or '', )
It uses an accumulator that is a tuple of two elements. The first one is a list of complete strings, and the second one is the remaining - incomplete - string. We can use this function with the scan operator to process the data:
rx.from_(source).pipe( ops.scan(unframe, seed=([],'')), )
But we cannot use it directly because it emits the complete accumulator instead of strings. It also emits all intermediate accumulator values where no full string is available:
([], 'each ni') (['each night'], '') ([], 'the seed grow') (['the seed grows up'], '') (['in the store galaxy'], '') Done!
Does this mean that the scan operator is useful only for trivial use-cases? Certainly not! This is the moment there we must compose several operators together.
Consider the result above. To emit only complete strings we have to:
- take the first element of the accumulator tuple
- drop values where the list is empty
- take the first entry of the list
As you may have guessed these are map, filter, and map transforms. So in the end, the full processing of the source data is this:
rx.from_(source).pipe( ops.scan(unframe, seed=([],'')), ops.map(lambda i: i[0]), # take string list ops.filter(lambda i: len(i) > 0), # drop empty lists ops.map(lambda i: i[0]), # take first string )
The complete code of this program is:
source = [ "each ni", "ght\n", "the seed grow", "s up\n", "in the store galaxy\n", ] def unframe(acc, i): lines = i.split('\n') lines[0] = acc[1] + lines[0] return ( lines[0:-1], lines[-1] or '', ) rx.from_(source).pipe( ops.scan(unframe, seed=([],'')), ops.map(lambda i: i[0]), ops.filter(lambda i: len(i) > 0), ops.map(lambda i: i[0]), ).subscribe( on_next=print, on_error=print, on_completed=lambda: print("Done!"), )
And it emits one item per complete string:
each night
the seed grows up
in the store galaxy
Done!
We used four operators to implement this feature. If we need to do more transforms, our pipe will end up being quite long, difficult to read, with no part being reusable in other applications. To solve all these problems, we can implement a new unframe operator simply:
def unframe(): def _unframe(acc, i): """unframes a string buffer acc is a tuple of two elements: - first element is an array of complete lines - second element is the current content of incomplete line """ lines = i.split('\n') lines[0] = acc[1] + lines[0] return ( lines[0:-1], lines[-1] or '', ) return rx.pipe( ops.scan(_unframe, seed=([],'')), ops.map(lambda i: i[0]), ops.filter(lambda i: len(i) > 0), ops.map(lambda i: i[0]), )
Note how a sub-pipe is constructed and returned. This new observable can be used in the main pipe of the application:
rx.from_(source).pipe( unframe(), )
This is much more readable. We can reuse the unframe operator in another application. As a bonus, we can unit-test the unframe operator.
So things are already quite good. But if we consider the following input data:
source = [ "each night\nthe seed grows up\nin the store galaxy\n", ]
The unframe operator will emit only one string, the first one. This is because, in the last step, we take only the first entry of the list. But in fact, we must emit several items when one item is received.
It is time for the fourth Musketeer to come and help us!
Flat Map
Last but not least, the flat map operator is also one of the base operators that are always used. It is very versatile and opens the door to higher-order observables. Details on higher-order observables will be part of another article. Let's focus on its simple usage for now: Emitting several items for each received item. Consider this example:
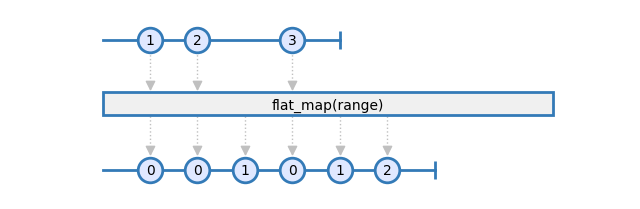
For each input item that is received, a range of items is emitted. While the filter operator removes input items, the flat_map operator adds new items.
- The flat_map operator takes a function as an argument.
- This function is called for each input item being received.
- It returns an observable
- The items of this observable are serialized as output items of the flat_map operator.
So the final implementation of the unframe operator is this:
return rx.pipe( ops.scan(_unframe, seed=([],'')), ops.map(lambda i: i[0]), ops.filter(lambda i: len(i) > 0), ops.flat_map(lambda i: rx.from_(i)), )
And the result is the expected one:
each night
the seed grows up
in the store galaxy
Done!
Conclusion
With only four operators, many transforms can be applied to data, and new operators can be implemented. Obviously, these are not - always - enough to implement a full application, but they are the foundation. The fact is that many RxPy operators are implemented as a composition of these ones.
Composition is key to ReactiveX. This is what makes ReactiveX extensible without any limitation. Since most applications require specific transforms, it means that the framework will never restrict an implementation!
 Interested in reactive programming ? Here is my book on
Reactive Programming with Python. I wrote this book to explain how to develop RxPY applications step by step.
Interested in reactive programming ? Here is my book on
Reactive Programming with Python. I wrote this book to explain how to develop RxPY applications step by step.